Let’s say you’re a service manager at a company using Dynamics 365 Field Service.
One of your team members tries using a chatbot (built with a large language model) to help with a quick question:
“Can I cancel a technician’s visit less than 12 hours before the appointment?”
The bot immediately replies:
“Yes, go to the work order, click ‘Cancel Booking,’ and you’re done!”
Sounds good. So, your team cancels the visit.
But here’s the problem:
Your company has a custom rule in Dynamics 365 that doesn’t allow cancellations under 12 hours without the manager’s approval.
That rule was added after the chatbot’s training data was created.
The bot didn’t know about your internal process because it wasn’t connected to your documentation or rules.
Now a technician shows up confused, the customer is frustrated, and your team gets blamed for “not following the process.”
Without RAG, this is exactly what happens:
The model guesses based on outdated or general public info.
It can’t access your company’s policies or up-to-date instructions.
It gives answers that sound right but may be completely wrong for your setup.
RAG in AI is built to solve exactly this problem...bridging the gap between static models and real-world, ever-changing knowledge.
If you want AI that’s not just smart, but aware, reliable, and ready to scale your business, then Retrieval-Augmented Generation isn’t optional; it’s foundational.
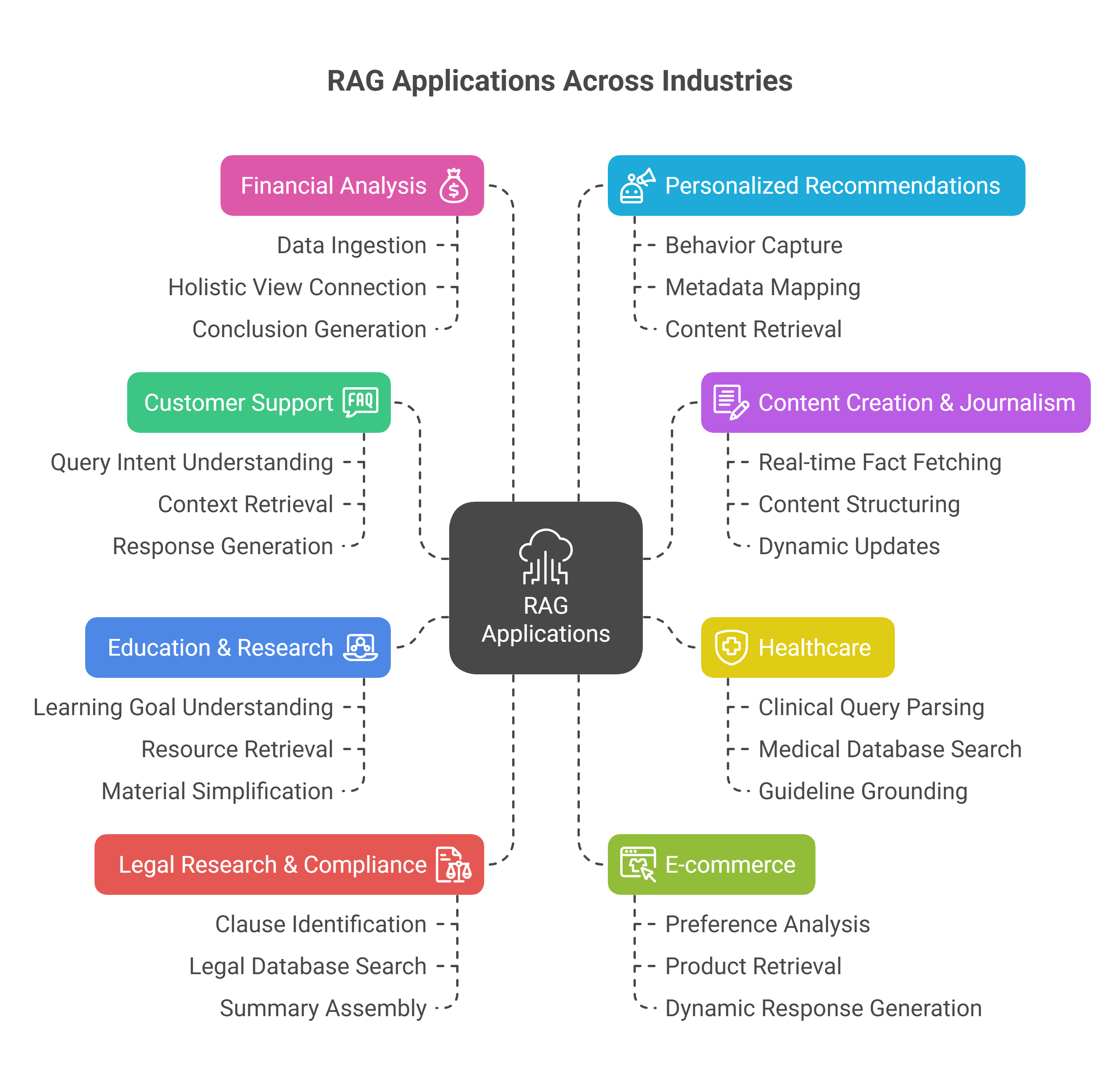
What is RAG in AI?
Retrieval-Augmented Generation (RAG) is a technique that enhances the output of Large Language Models (LLMs) by integrating retrieved information from external, authoritative sources into the generation process. Instead of relying solely on what a model “remembers” from its training data, RAG injects relevant, real-time, and domain-specific knowledge into the prompt before generating an answer.
At its core, RAG consists of two key components:
- Retriever – Searches external data (documents, APIs, knowledge bases) and fetches relevant content.
- Generator – Uses that content along with the user query to generate a grounded, accurate response.
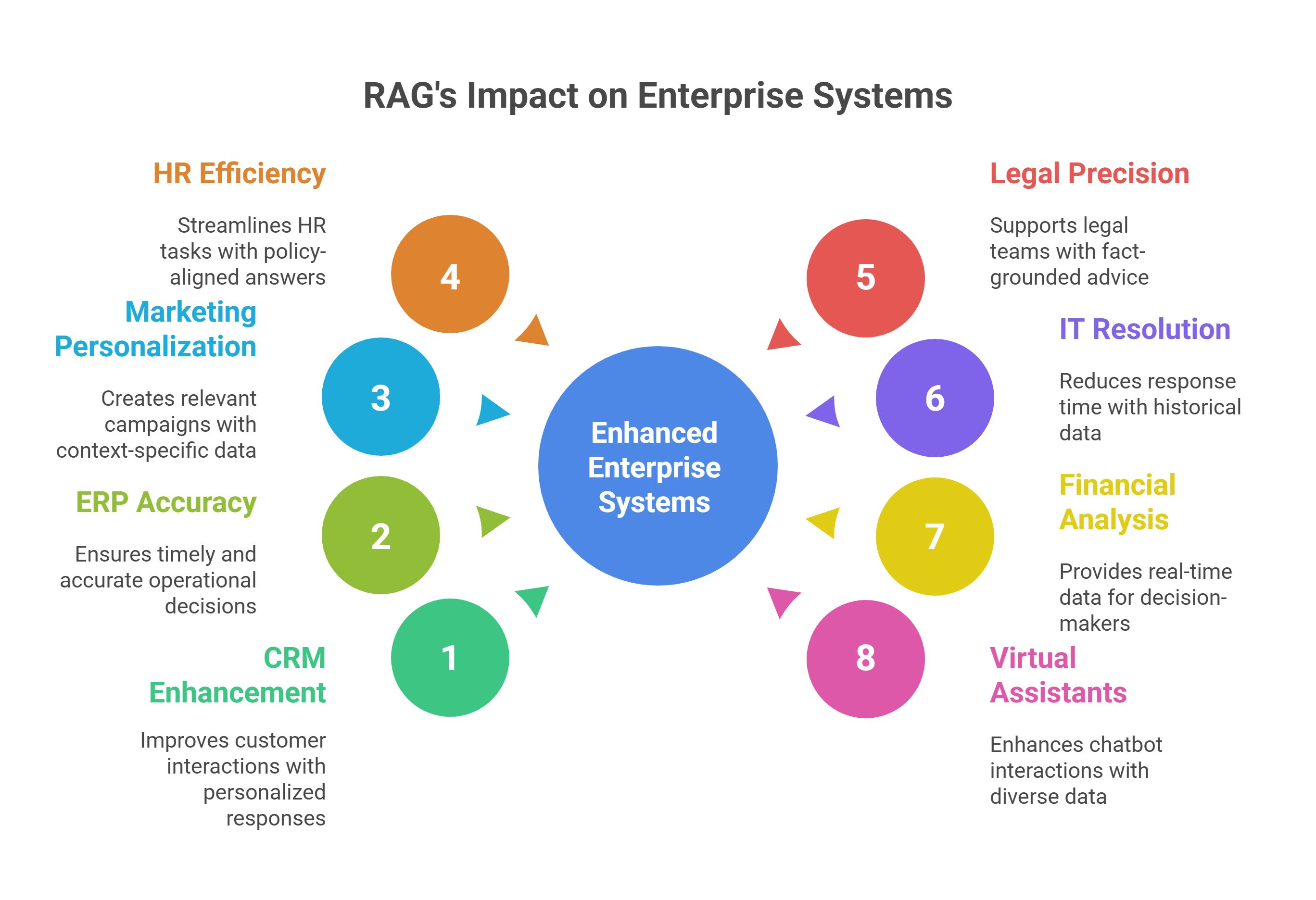
By combining these steps, RAG dramatically reduces hallucinations, improves adaptability to niche domains (like healthcare or enterprise IT), and makes responses more reliable, traceable, and current.
RAG is especially useful when:
- You want the AI to pull in live or recent information (news, research, HR policies).
- You want to ensure the AI response is based on actual facts from your own systems or documents.
- You don’t want to retrain the whole model, which is expensive and slow.
Also, check out our detailed guide on Agentic AI vs. AI Agents to see how they compare and when to use each.
RAG’s Evolution and Ecosystem
RAG in AI has come a long way in just a few years. Here's a simplified view of how it started and where it’s headed.
1. The Early Days: Naïve RAG
The first RAG systems used basic keyword matching. If you asked a question about “solar panels,” it would only search for that exact word. If your documents used “photovoltaic cells” instead, it missed the point. These systems were fast but often returned shallow or irrelevant results.
2. Smarter Retrieval: Semantic RAG
Next came semantic search. This version understood meaning, not just keywords. So, if you asked about “renewable energy,” it could find relevant content even if those exact words weren’t used. It improved accuracy and helped AI generate more thoughtful and connected answers.
3. More Flexibility: Modular RAG
As businesses needed more control, modular RAG allowed teams to:
- Mix and match keyword and semantic search
- Connect to APIs or external tools
- Customize how retrieval and generation work for specific use cases (like legal, customer service, or support bots)
This made RAG more usable across different departments and industries.
4. Deeper Reasoning: Graph-Based RAG
Some queries need more than one piece of information. Graph RAG introduced the ability to connect multiple data points, like stitching together timelines, events, or relationships. It helps when questions are layered or require steps, like asking for the history behind a product or law.
5. Autonomous and Adaptive: Agentic RAG
The most recent evolution is Agentic RAG. These systems can:
- Make decisions on their own (like which documents to trust)
- Improve responses over time with feedback
- Adjust based on speed, accuracy, or user intent